
Friday lunch and learn: ML papers, vol. 2
Information is a fountain from which we must drink deeply and process carefully

Sparse autoencoders at scale
OpenAI’s “Extracting Concepts from GPT-4” announcement yesterday links to a paper “Scaling and evaluating sparse autoencoders” (Gao et al., OpenAI, 2024), out of OpenAI’s former Superalignment Interpretability team. They’ve included a useful sparse autoencoder visualizer (see: Patrick/Patty surname predictor under GPT-2 small features).
Succinctly: “At the heart of every deep network lies a linear transformation followed by an activation function f(·),” (Ramachandran et al., Google Brain, 2017), and “Deep networks with ReLUs [Rectified Linear Unit, activation function f(x)=max(x,0)] are more easily optimized than networks with sigmoid or tanh units, because gradients are able to flow when the input to the ReLU function is positive.”
Thus the OpenAI team proposes baseline ReLU autoencoders trained on residual streams of GPT-2 small and “models from a series of increasing sized models sharing GPT-4 architecture and training setup, including GPT-4 itself”. They use a k-sparse autoencoder “which directly controls the number of active latents by using an activation function (TopK) that only keeps the k largest latents (e.g. hidden nodes), zeroing the rest”.
As it stands, as the size of a language model increases, the risk and prevalence of what the authors term here dead latents (aka hidden nodes that “stop activating entirely at some point in training”) increases with it, resulting in “substantially worse MSE (mean-squared error) and “computationally wasteful [training]”.
The rest of the paper is eval-focused — which I love to see because I’ve always felt model evaluation theory (design, scalability, and applications) doesn’t get enough attention (pun intended) — notably:
our autoencoders find many features that have quickly recognizable patterns that suggest explanations when viewing random activations […] “illusion” of interpretability
Unfortunately, precision is extremely expensive to evaluate when the simulations are using GPT-4 as in Bills et al. [2023]. As an initial exploration, we focus on an improved version of Neuron to Graph (N2G) [Foote et al., 2023], a substantially less expressive but much cheaper method that outputs explanations in the form of collections of n-grams with wildcards
And end on a promising note of connecting to this star-studded paper “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer” (feat. Geoffrey Hinton and Jeff Dean) proposing a Mixture-of-Experts (MoE) layer (up to thousands of feed-forward sub-networks).
The LLM data frontier
Epoch AI, an AI governance-focused research institute (fun fact: OpenAI also started out as a full nonprofit) entering the scene in a bigger way recently (TIME coverage), published “Will we run out of data? Limits of LLM scaling based on human-generated data” a few days ago:
“we argue that human-generated public text data cannot sustain scaling beyond this decade[…] we develop a model of the growing demand for training data and the production of public human text data. We use this model to predict when the trajectory of LLM development will fully exhaust the available stock of public human text data.”
Importantly, “Leading AI researchers have expressed concerns about data availability limiting the progress of machine learning systems”, as data scarcity mitigation techniques might include “repeating data, adding more code data, and relaxing the quality filters used during data preprocessing” and “both repeating data and including more code data can compensate for a decrease of up to 75% in the text data budget” but not without performance loss.
Dario Amodei, the CEO of Anthropic, estimates a 10% chance that the scaling of AI systems could stagnate due to insufficient data.
Epoch’s model of data scarcity involves two variables: data stock (total amount of public human text data available for use) and dataset size (amount actually used in practice to train LLMs). These could be projected based on historical trends, but the researchers highlight a data quality point that “not all public human text data is created equal” but critically there is “no standard accepted measure of data quality” so they devise this heuristic:
A dataset is of higher quality than another if training on it leads to higher performance, at similar dataset sizes.
Finally, “The median exhaustion year is 2028, and by 2032 exhaustion becomes very likely. At the point the data stock is fully utilized, models will be using around 5e28 FLOP during training.” [Assuming models are trained compute-optimally, which is not the case in reality, hence the 5x overtraining assumption]
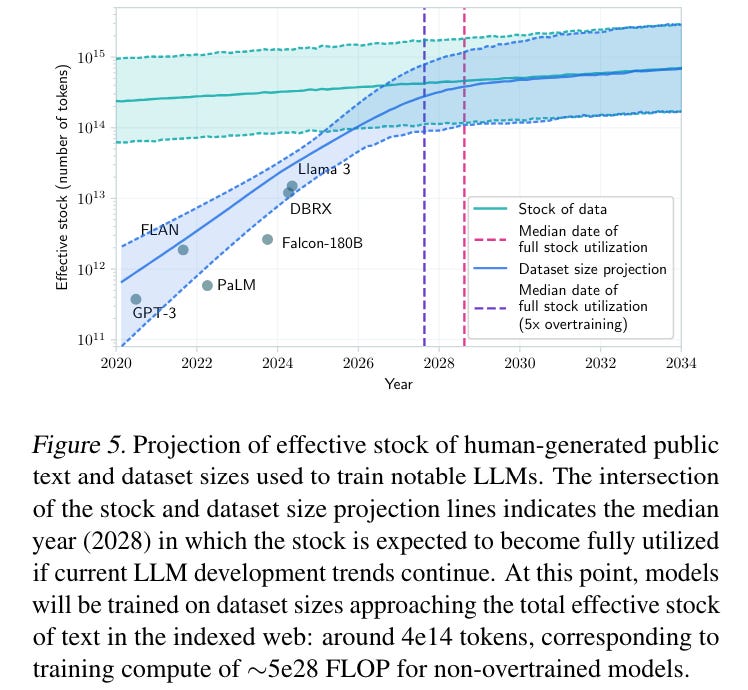
My first thoughts when reading this paper were what about synthetic data? and what about multimodal? which the authors addressed immediately in Beyond public human text data: “We consider synthetic data to be one of the most promising avenues for circumventing data bottlenecks” and reference GPT-4V (trained on image and text data) (and now GPT-4o for audio), still roughly estimating that “current video and image stocks are not large enough to prevent a data bottleneck”.
Ultimately,
after accounting for steady improvements in data efficiency and the promise of techniques like transfer learning and synthetic data generation, it is likely that we will be able to overcome this bottleneck in the availability of public human text data.
Our results highlight the need for further research to quantify data efficiency growth rates and the potential performance gains from emerging methods.
OG special
I lost the tweet, but someone recommended this Chris Olah blog post “Neural Networks, Manifolds, and Topology”.
It’s interesting to read this in 2024 as every new (and old) player on the scene seems to be building a GPT wrapper and leveraging the power of generative AI, the new silver bullet-apparent, to disrupt cloud / gaming / productivity / supply chain / climate / education / entertainment / etc. Chris Olah put it best, even as he was speaking on vanilla neural networks: “there remain a number of concerns about them.”
Then he presents a beautifully mathematical, proof-based explanation of now less-discussed underlying concepts:
The manifold hypothesis is that natural data forms lower-dimensional manifolds in its embedding space… If you believe this, then the task of a classification algorithm is fundamentally to separate a bunch of tangled manifolds.
Only the best mathematical minds can reason through space and probability this way. I’m running out of my self-imposed writing time limit to dig in more here but will share this illustration of how deeply mathematically-rooted neural networks (and every derivative of them) are; they’re deep probability machines, after all.
The task of the machine learning researcher is to design these machines in a way that is effective, namely making accurate predictions; a more advanced researcher thinks about the self-consistency of the machine, how much duplicate information it contains and how we can be more efficient about both how much the information we store and how much we need at each node of these networks. Given sufficiently independent segments, engineers may consider how we sequence and parallelize training to operate at scale and keep up with the pace of human development itself.
High responsibility, high reward.
Acknowledgements: Deepest thanks to Shreya Shankar, ML superstar and a lifelong friend, and all the very nice researchers that posted blog posts that inspired and informed me. Hope to meet you all in person someday.
I work in software (not an ML expert) and post blog posts every week to share my learnings and opinions. Please reach out on Twitter!