
I like big books and I cannot lie
Please don't come after me for this title

An old friend of mine (Anant) sent me this paper recently and I wanted to take this opportunity to both do a careful reading of the paper, highlight an example from the Databricks Big Book of Machine Learning Use Cases (as Databricks Data + AI Summit is on the mind), and walk through a Snowflake blog post (with DSPy).
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? (Gekhman et al., Technion, Google, 2024)
We demonstrate that large language models struggle to acquire new factual knowledge through fine-tuning, as fine-tuning examples that introduce new knowledge are learned significantly slower than those consistent with the model’s knowledge. However, we also find that as the examples with new knowledge are eventually learned, they linearly increase the model’s tendency to hallucinate.
This paper proposes a framework to assess “whether a single fine-tuning example is consistent with the model’s knowledge”: “SliCK, a hierarchy of four knowledge categories, derived from a continuous measure that quantifies the agreement between model-generated answers and the ground-truth labels”. Measurement is performed on closed-book (no-context) QA by categorizing examples into known and unknown (highly known, maybe known, weakly known) and varying ratio of fine-tuning examples categorized as unknown, controlling for other variables.
This seems intuitive, even (dare I say) trivial until we get to the kicker of the paper: “empirically demonstrates that learning from Unknown fine-tuning examples is linearly correlated with the model’s tendency to hallucinate w.r.t. its pre-existing knowledge”. I’ve bolded this linear correlation twice in the last three paragraphs because that is actually not intuitive to me and could only be proven to me via the experimental framework and results this paper presents.
We saw that Unknown examples are fitted slower than the Known ones, thus their negative effect manifests as a form of overfitting, which emphasizes the importance of using early-stopping instead of a fixed number of finetuning steps. However, early-stopping may be less effective when fine-tuning on numerous tasks with distinct optimal stopping points. An alternative solution can be to align the fine-tuning data with the model’s knowledge by filtering-out Unknown examples. We show initial evidence that this can reduce the risk of overfitting without compromising performance.
Detecting Financial Fraud at Scale With Decision Trees and MLflow on Databricks, Databricks Big Book of ML Use Cases
If you’ve ever received a call from your bank asking to confirm suspicious transactions, you have firsthand experience with the outcomes of financial fraud detection. (In many cases it may be a false positive I much prefer an over-sensitive model to an under-sensitive one.) As the authors note,
There is a certain degree of reluctance with regard to machine learning models in the financial world, as they are believed to offer a “black box” solution with no way of justifying the identified fraudulent cases.
On the flip side, last night a friend mentioned to me that maps technologies on smartphones involve neural nets on gyroscope and accelerometer data, which can explain why the cold-start labeled GPS direction (when you open a maps app for the first time) is often off before it can re-calibrate. It’s ironic but not surprising (and understandable given risk levels involved) that financial firms may shy away from using nondeterministic models to detect unpredictable, real-time mission-critical events such as fraud, while technology firms innovate by applying deep learning to modern iterations of centuries-old technologies (the compass, the watch, the calculator).
In the financial fraud detection case:
the concern with machine learning models being difficult to interpret may be further assuaged if a decision tree model is used as the initial machine learning model… The additional benefit is, of course, the utmost transparency of the model, which will essentially show the decision-making process for fraud, but without human intervention and the need to hard code any rules or thresholds… Having interpretable features will yield interpretable and defensible model results.
At this level of statistical and probabilistic modeling the difference between theory and engineering is the question of infrastructure supporting application at scale (see Anthropic’s engineering challenges of scaling interpretability), and in this example by Databricks they choose to focus on data gaps at scale after solving the question of model interpretability by using decision tree rule-based models:
Training a supervised machine learning model to detect financial fraud is very difficult due to the low number of actual confirmed examples of fraudulent behavior… the presence of a known set of rules that identify a particular type of fraud can help create a set of synthetic labels and an initial set of features.
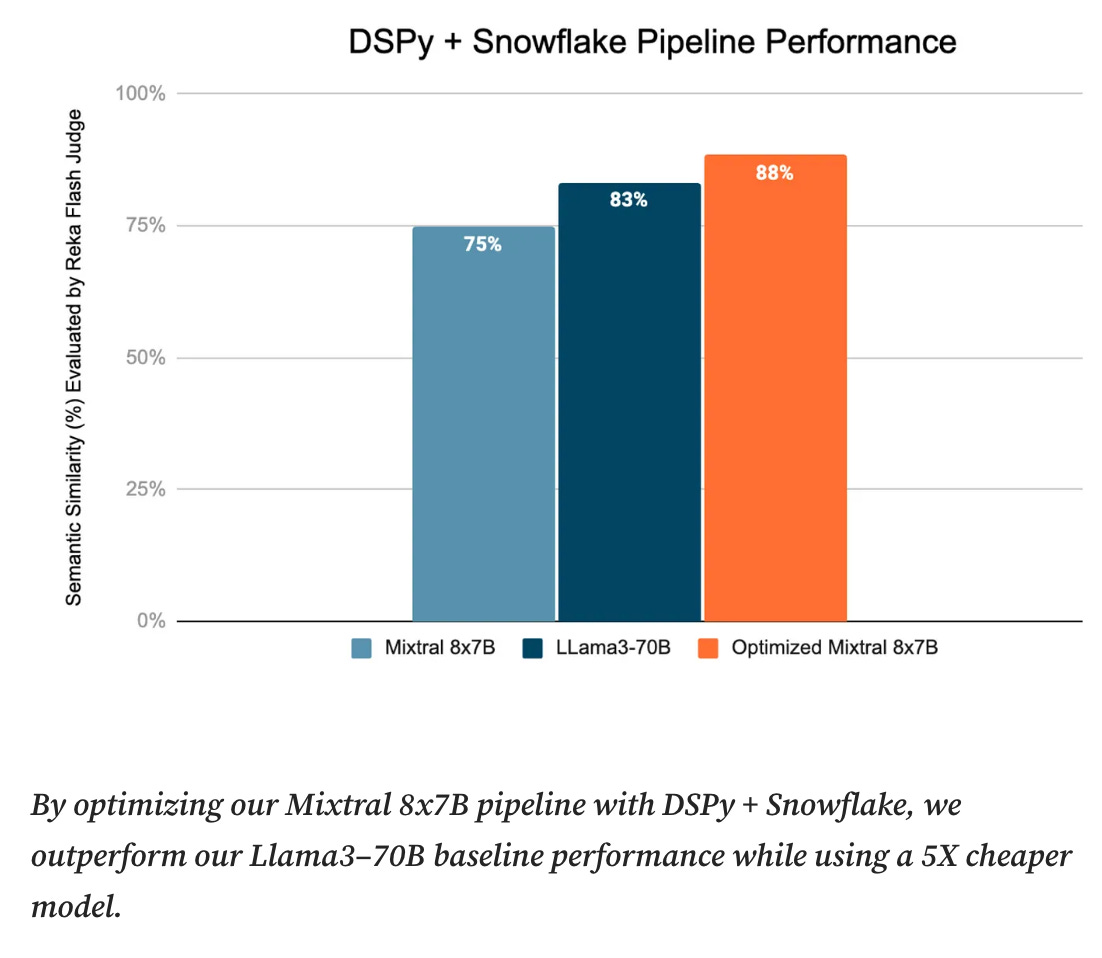
Re: DSPy + Snowflake: Towards Secure, Future-Proof, and Cost Efficient LLM Pipelines
This blog post is quite comprehensive and concisely written, so just sharing and letting it speak for itself. (Discovered via Omar Khattab on Twitter.)
Thanks for reading! This post is short but hopefully sweet. You can call me beep me on Twitter.