
Let's drop everything and go DeepSeek diving
DeepSeek really made waves this week

This week Chinese AI research lab DeepSeek took the AI industry (and Twitter) by storm by open-sourcing DeepSeek-R1, a “model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step” performing at the level of OpenAI o1 series models on a number of benchmarks.
According to WIRED, DeepSeek started as a deep learning research arm of High-Flyer, a Chinese quant hedge fund established less than ten years ago:
focused on PhD students from China’s top universities… who were eager to prove themselves. […] The hiring strategy helped create a collaborative company culture where people were free to use ample computing resources to pursue unorthodox research projects […] For many Chinese AI companies, developing open source models is the only way to play catch-up with their Western counterparts, because it attracts more users and contributors, which in turn help the models grow.
I am quite literally rubbing my hands as I get ready to read this paper. Let’s get into it.
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, DeepSeek-AI (2025)
DeepSeek has open sourced “DeepSeek-R1-Zero, DeepSeek-R1, and six dense models (1.5B, 7B, 8B, 14B, 32B, 70B) distilled from DeepSeek-R1 based on Qwen and Llama”. (Qwen is developed by Alibaba Cloud. Llama may be more familiar to Americans — Meta’s open-source AI models.)
In their paper, DeepSeek publishes results benchmarked against OpenAI o1 models, which was first introduced as a “new LLM trained with RL” — “chain of thought” reasoning with the idea that having the model “think for longer” and learn mechanically how to structure and reason could generate better results — DeepSeek-R1 outperforms OpenAI o1 models on AIME (competitive math) and SWE-bench (GitHub issue resolution ability), performs on par in Codeforces (competitive coding), MMLU (covers 57 subjects from elementary to advanced professional level), GPQA (graduate level sciences) and MATH-500 (subset of OpenAI’s own math benchmark).
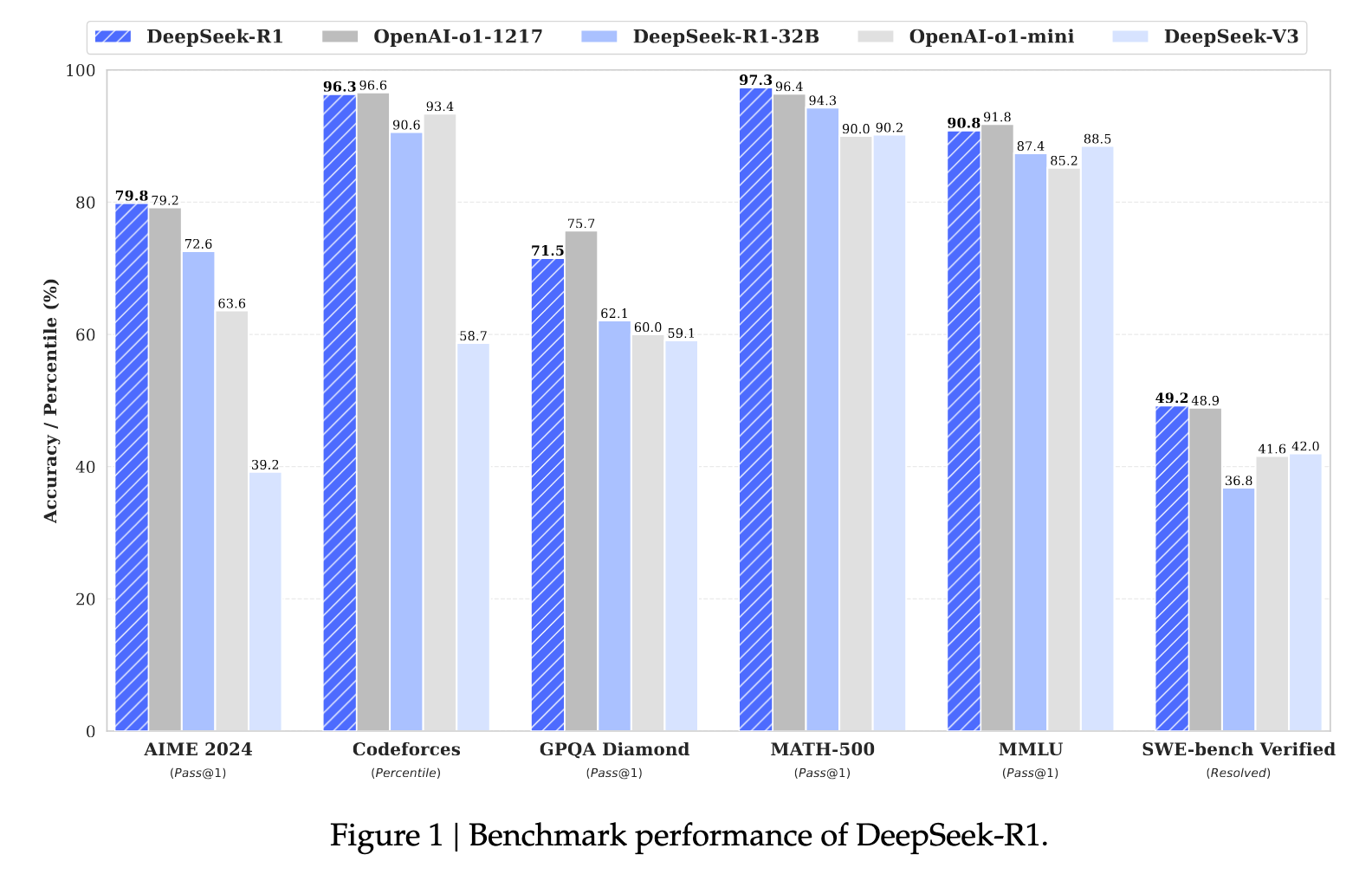
DeepSeek’s approach is unique because they set out explicitly to investigate the capability of LLMs to “develop reasoning capabilities without any supervised data, focusing on their self-evolution through a pure RL process”. DeepSeek-R1-Zero, the product of applying GRPO (Group Relative Policy Optimization, a DeepSeek RL algorithm originally developed to come after SFT) directly to DeepSeek-V3-Base model skipping supervised fine-tuning is able to match AIME performance of OpenAI-o1-0912 after “thousands of RL steps” but run into other problems like “poor readability and language mixing”, so incorporate “a small amount of cold-start data and a multi-stage training pipeline” for DeepSeek-R1.
— liner notes: DeepSeek-V3-671B beats Llama-3.1-405B model performance at a literal fraction of the training cost —
DeepSeek-V3-Base was released last month and estimated the total cost of training the 671B parameter model at $5.6 million (based on requiring “2.788M [NVIDIA] H800 GPU hours for its full training” — by the way, US regulation of AI chip exports is something to watch).
Model training cost is notoriously expensive and opaque in this industry, with Sam Altman cited as claiming training cost of OpenAI’s trillion-parameter GPT-4 at “more than $100 million” and Anthropic’s Dario Amodei projecting a $10 billion model by 2025.
Let’s do some back-of-the-envelope calculation for an apples to apples comparison to DeepSeek-V3’s (671B parameter) training costs; take Meta’s Llama 3.1 (405B parameters), which required 39.3M [NVIDIA H100] GPU hours. NVIDIA H800 GPUs are H100 GPUs formulated for Chinese export; “H800 mainly reduced the chip-to-chip data transfer rate to about half the rate of the flagship H100.” Rental costs seem similar between H100 and H800, at $2 per GPU hour DeepSeek assumes in their calculation so let’s just use that. That means Llama-3.1-405B cost $78.6M to train vs. DeepSeek-V3-671B at $5.6M, more than an order of magnitude difference, and DeepSeek-V3-671B was able to outperform Llama-3.1-405B in a slate of general and competitive reasoning benchmarks.
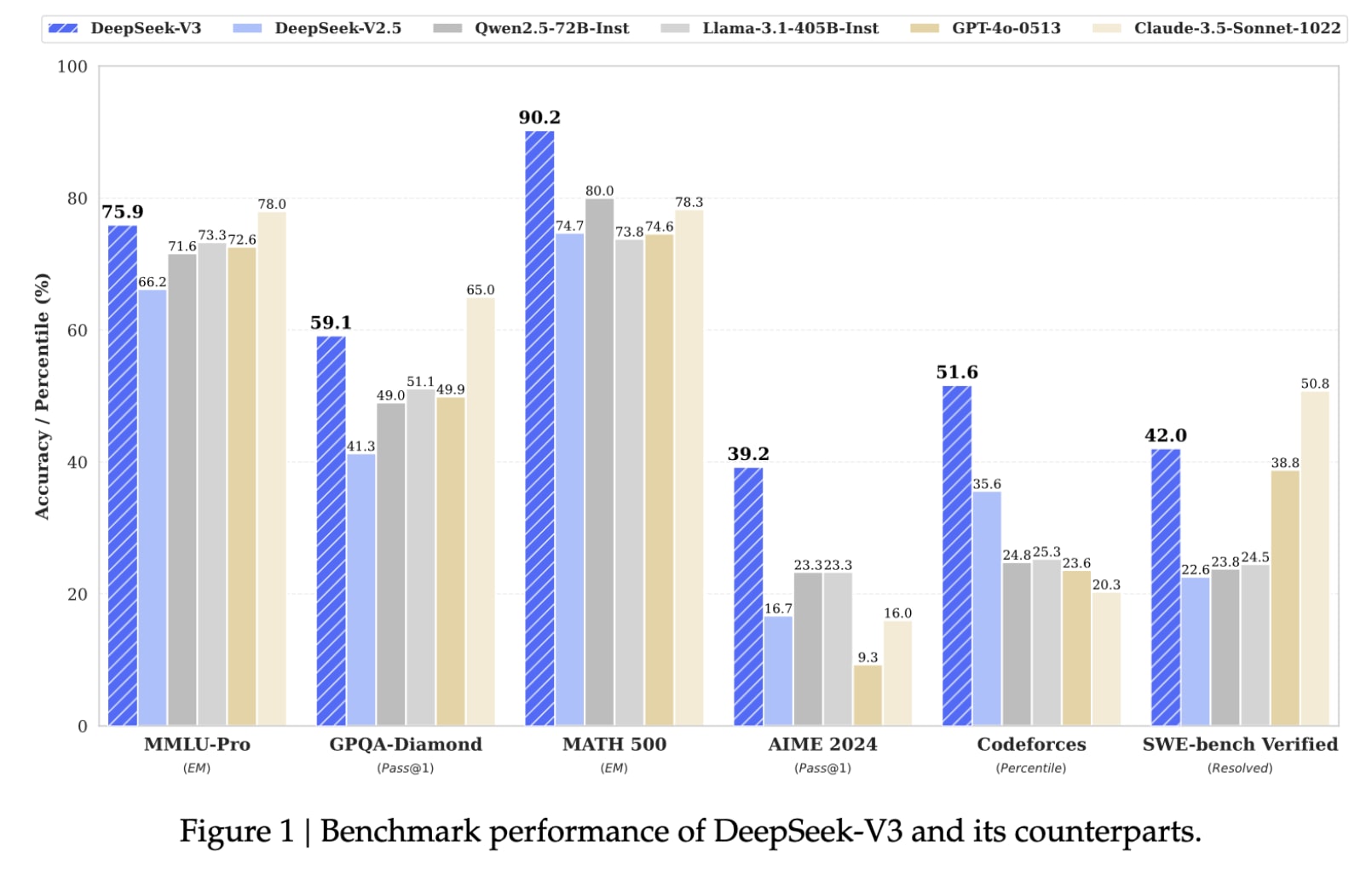
DeepSeek is able to achieve this unprecedently low training cost by designing a FP8 mixed precision training framework, an approach first published in 2023 out of Microsoft Azure and Research leveraging low-bit data formats to reduce LLM training cost.
— end liner notes —
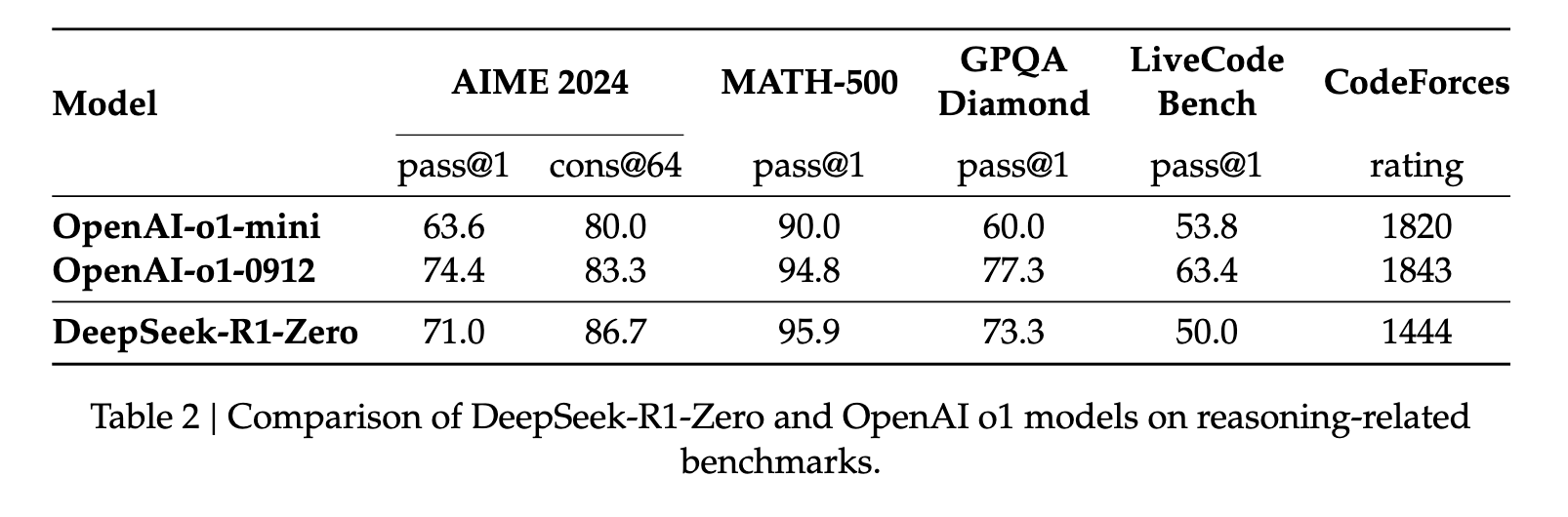
Back to the DeepSeek-R1 paper. We’re still analyzing DeepSeek-R1-Zero, which is kept cheap by using GRPO for pure RL and forgoing supervised fine-tuning.
At this stage DeepSeek-R1-Zero is competitive with OpenAI o1 models across benchmarks and takes more time to respond as RL steps increase by the thousands, a marker of the model developing an “intelligence”.
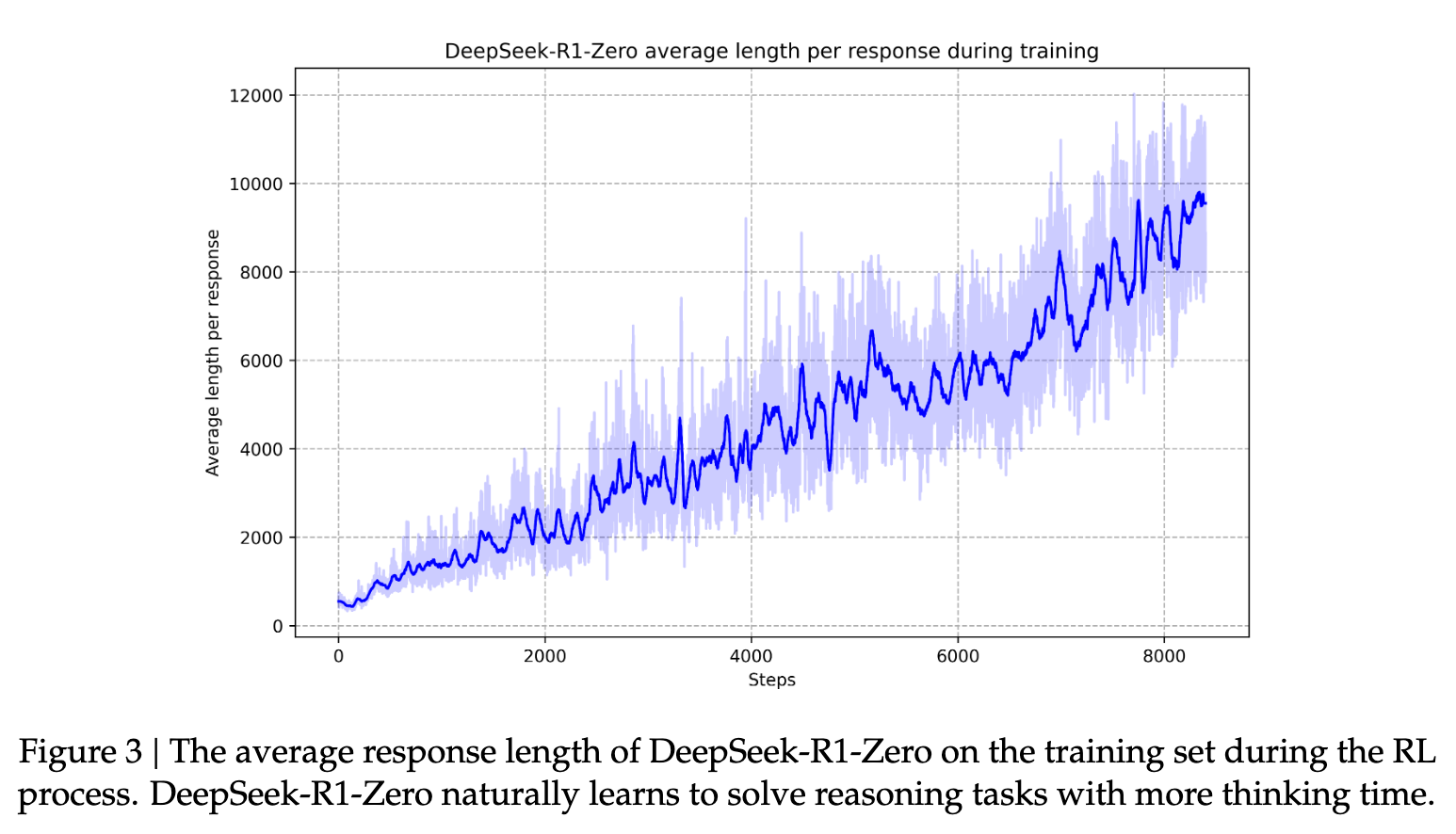
I genuinely love it when deep appreciation for the craft comes through in any research paper, and want to highlight this section:
One of the most remarkable aspects of this self-evolution is the emergence of sophisticated behaviors as the test-time computation increases. Behaviors such as reflection—where the model revisits and reevaluates its previous steps—and the exploration of alternative approaches to problem-solving arise spontaneously. These behaviors are not explicitly programmed but instead emerge as a result of the model’s interaction with the reinforcement learning environment. This spontaneous development significantly enhances DeepSeek-R1-Zero’s reasoning capabilities, enabling it to tackle more challenging tasks with greater efficiency and accuracy.
Aha Moment of DeepSeek-R1-Zero A particularly intriguing phenomenon observed during the training of DeepSeek-R1-Zero is the occurrence of an “aha moment”. This moment… occurs in an intermediate version of the model. During this phase, DeepSeek-R1-Zero learns to allocate more thinking time to a problem by reevaluating its initial approach. This behavior is not only a testament to the model’s growing reasoning abilities but also a captivating example of how reinforcement learning can lead to unexpected and sophisticated outcomes.
This moment is not only an “aha moment” for the model but also for the researchers observing its behavior. It underscores the power and beauty of reinforcement learning: rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies. The “aha moment” serves as a powerful reminder of the potential of RL to unlock new levels of intelligence in artificial systems, paving the way for more autonomous and adaptive models in the future.
Of course, there’s a catch to DeepSeek-R1-Zero. You can’t expect a model effectively allowed to teach itself succeed in all tasks, even after thousands of iterations, and DeepSeek addresses the “poor readability and language mixing” alluded to earlier by “construct[ing] and collect[ing] a small amount of long CoT data to fine-tune the model as the initial RL actor” to produce DeepSeek-R1.
On the flip side, DeepSeek also produces distilled models that directly fine-tune Qwen and Llama (applying only SFT now without an RL stage) “using the 800k samples curated with DeepSeek-R1”, proposing it as a method to “equip more efficient smaller models with reasoning capabilities”. On the relative tradeoffs between SFT-forward (distillation) and RL-forward methods:
Distilling more powerful models into smaller ones yields excellent results, whereas smaller models relying on the large-scale RL mentioned in this paper require enormous computational power and may not even achieve the performance of distillation… While distillation strategies are both economical and effective, advancing beyond the boundaries of intelligence may still require more powerful base models and larger-scale reinforcement learning.
Finally, it’s nice to see an explicit callout on Unsuccessful Attempts in training, including a failure of an AlphaGo-inspired Monte Carlo Tree Search approach to scale in an exponentially growing token generation defined search space as opposed to a relatively well-defined search space for a board game.
This was my favorite paper to read in a while because the researchers’ genuine curiosity and excitement about the unflashy, conceptually simple reinforcement learning approach really came through. This paper was indeed “a powerful reminder of the potential of RL to unlock new levels of intelligence in artificial systems.”