
Let's talk about foundation models

Yesterday Meta released Llama 3.1 405B, “the first frontier-level open source AI model”. [N.B. When I Googled “frontier-level” to understand what this might mean, I found a breakdown Frontier Airlines Elite Statuses — an unrelated but helpful reminder to fly Frontier more often!]
Developer’s notes:
Meta released a request for comment on the Llama Stack API
Semi-related: List of April Fools RFCs
Llama Guard 3 “is a high-performance input and output moderation model designed to support developers in detecting various common types of violating content, supporting even longer context across eight languages”
Prompt Guard categorizes prompts as benign, injection (data from untrusted sources that attempt to induce models to execute unintended instructions), and jailbreak (malicious instructions designed to override the safety and security features built into a model); Meta recommends “that AI developers fine-tune Prompt Guard with application-specific data.”
Paper: The Llama 3 Herd of Models, Meta AI
Foundation models: “Rather than develop AI from scratch, data scientists use a foundation model as a starting point to develop ML models that power new applications more quickly and cost-effectively. [Foundation models are] ML models trained on a broad spectrum of generalized and unlabeled data and capable of performing a wide variety of general tasks such as understanding language, generating text and images, and conversing in natural language.”
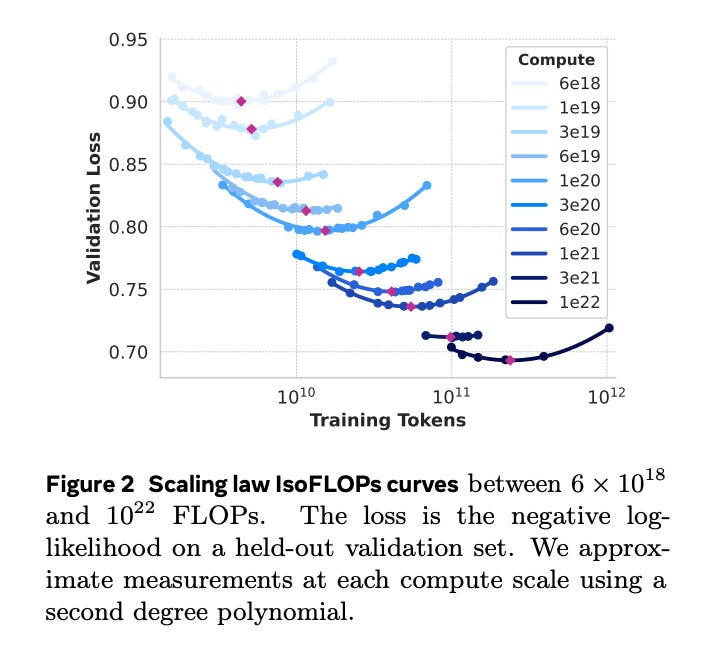
Scaling laws link a model’s properties (e.g. parameter count, dataset size) to its performance (loss); power laws are of the class y = b * x^a. Importantly, “scaling laws are not universal for ML models” — “Generative models such as large language models tend to follow regular scaling laws” but for “discriminative models such as image classifiers, clear scaling laws currently do not emerge”.
Richard Sutton’s "bitter lesson":
AI researchers have often tried to build knowledge into systems,
"This always helps in the short term [...], but in the long run it plateaus and it even inhibits further progress,
Breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning."
Meta researchers propose a three-lever framework for building high-quality foundation models along data (quantity and quality), scale (compute-optimal according to scaling laws), and managing complexity (scale the model development process).
Pre-training:
“curation and filtering of a large-scale training corpus”: knowledge dataset until end of 2023, remove PII, extract “high-quality diverse text” HTML, de-dupe, developed heuristics to filter out low-quality content, model-based quality filtering (e.g. `fasttext`), multilingual
“model architecture and corresponding scaling laws for determining model size”: “scaling law experiments in which we train several small models on a data mix and use that to predict the performance of a large model on that mix… repeat this process multiple times for different data mixes to select a new data mix candidate… train a larger model on this candidate data mix and evaluate the performance of that model on several key benchmarks” (“final data mix contains roughly 50% of tokens corresponding to general knowledge, 25% of mathematical and reasoning tokens, 17% code tokens, and 8% multilingual tokens”)… “standard, dense Transformer architecture… does not deviate significantly from Llama and Llama 2” with the addition of grouped query attention (GQA) and attention mask that prevents self-attention between different documents within the same sequence.”

“techniques for efficient pre-training at large scale”: Llama 1 and 2 were trained on Meta AI Research SuperCluster. Llama 3 was trained on Meta’s production clusters (up to 16K H100 GPUs, each running at 700W TDP with 80GB HBM3), Tectonic (Meta’s DFS), and RDMA over Converged Ethernet (RoCE) fabric.
“pre-training recipe”: (1) initial pre-training (including data mix adjustment), (2) long-context pre-training “train on long sequences to support context windows of up to 128K tokens. We do not train on long sequences earlier because the compute in self-attention layers grows quadratically in the sequence length”, and (3) annealing.
Post-training (aligning model with human feedback)
Finetuning data: “Prompts from our human annotation collection with rejection-sampled responses”, “Synthetic data targeting specific capabilities”
“techniques for categorizing topic, complexity, and quality of our data samples. In each round of post-training, we adjust our overall data mix carefully across these axes to tune performance across a wide range of benchmarks.”
Capabilities:
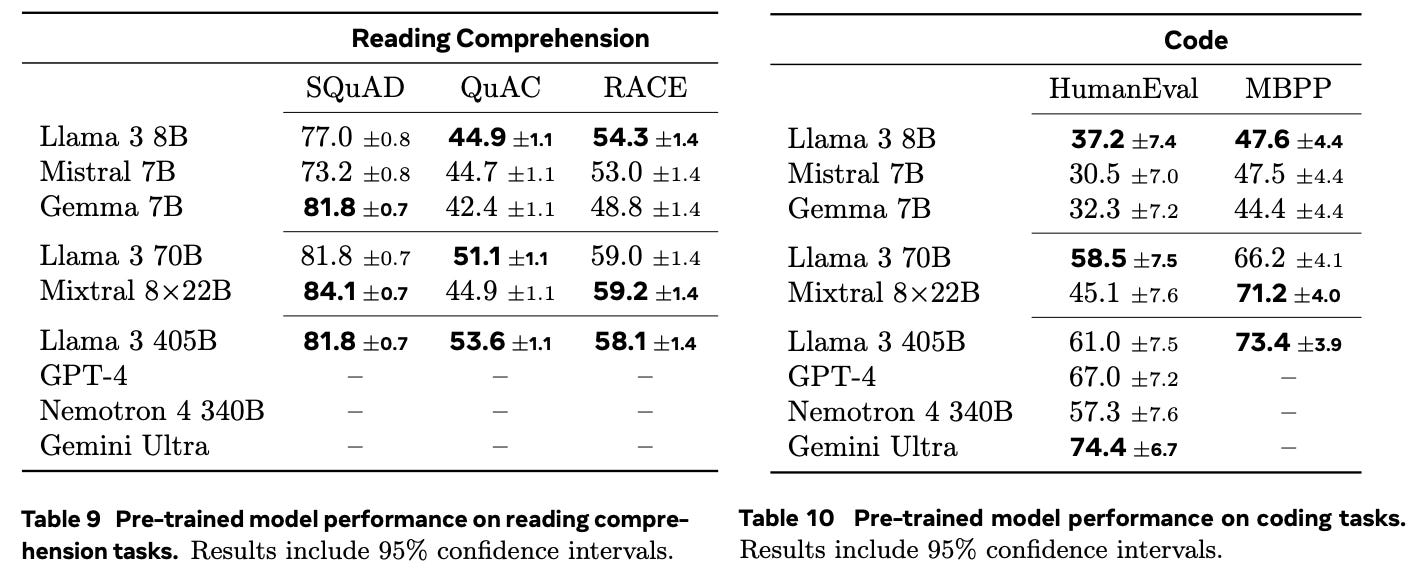
“For Llama 3, we target improving and evaluating code generation, documentation, debugging, and review capabilities for the following high priority programming languages: Python, Java, Javascript, C/C++, Typescript, Rust, PHP, HTML/CSS, SQL, bash/shell”
“Llama 3’s multilingual capabilities, including training an expert specialized on substantially more multilingual data, sourcing and generating high quality multilingual instruction tuning data for German, French, Italian, Portuguese, Hindi, Spanish, and Thai”
A comprehensive breakdown of the challenges facing accurate math and reasoning models, including lack of prompts and lack of ground truth chain of thought
“Teaching LLMs to use tools such as search engines or code interpreters”
On counteracting hallucinations: “We follow the principle that post-training should align the model to ‘know what it knows’ rather than add knowledge”
“Steerability is the ability to direct the model’s actions and outcomes to meet developer and user specifications.”
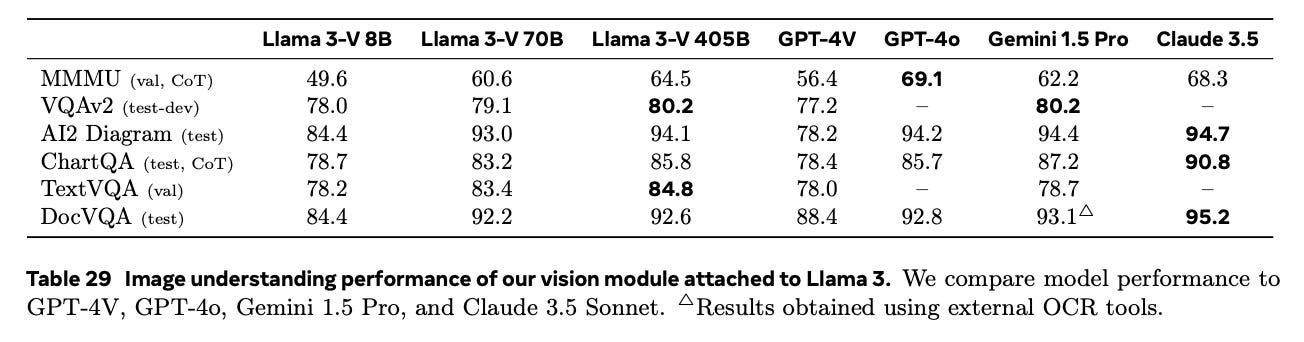
Meta dedicates a decent half of the paper to vision (image/video, image-text and video-text pairs) and speech experiments specifically in conjunction and parallel to language modeling (compositionally). I’m not super impressed with Llama 3’s image understanding performance relative to Claude 3.5’s:
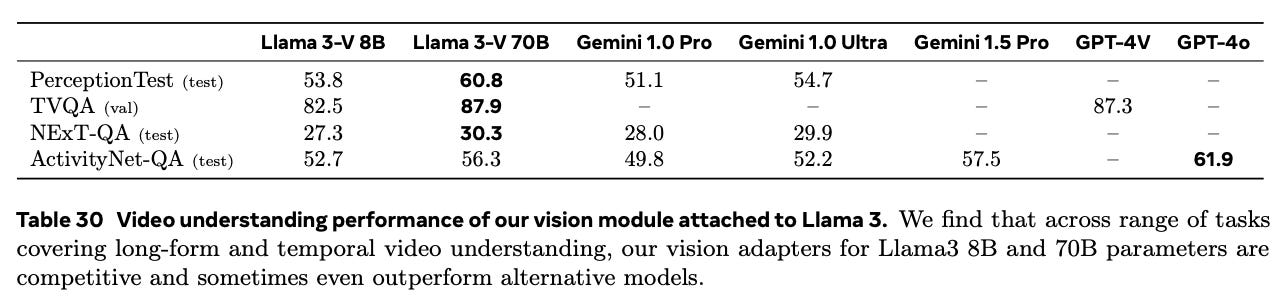
But there is significant coverage and quality lift in video understanding relative to other major models:
Llama 3 makes waves relative to other models in speech translation and re: safety, achieves “the lowest percentage of added toxicity for English [less than 1%]. It removes significantly more toxicity than it adds.”
Image that is worth a thousand words:
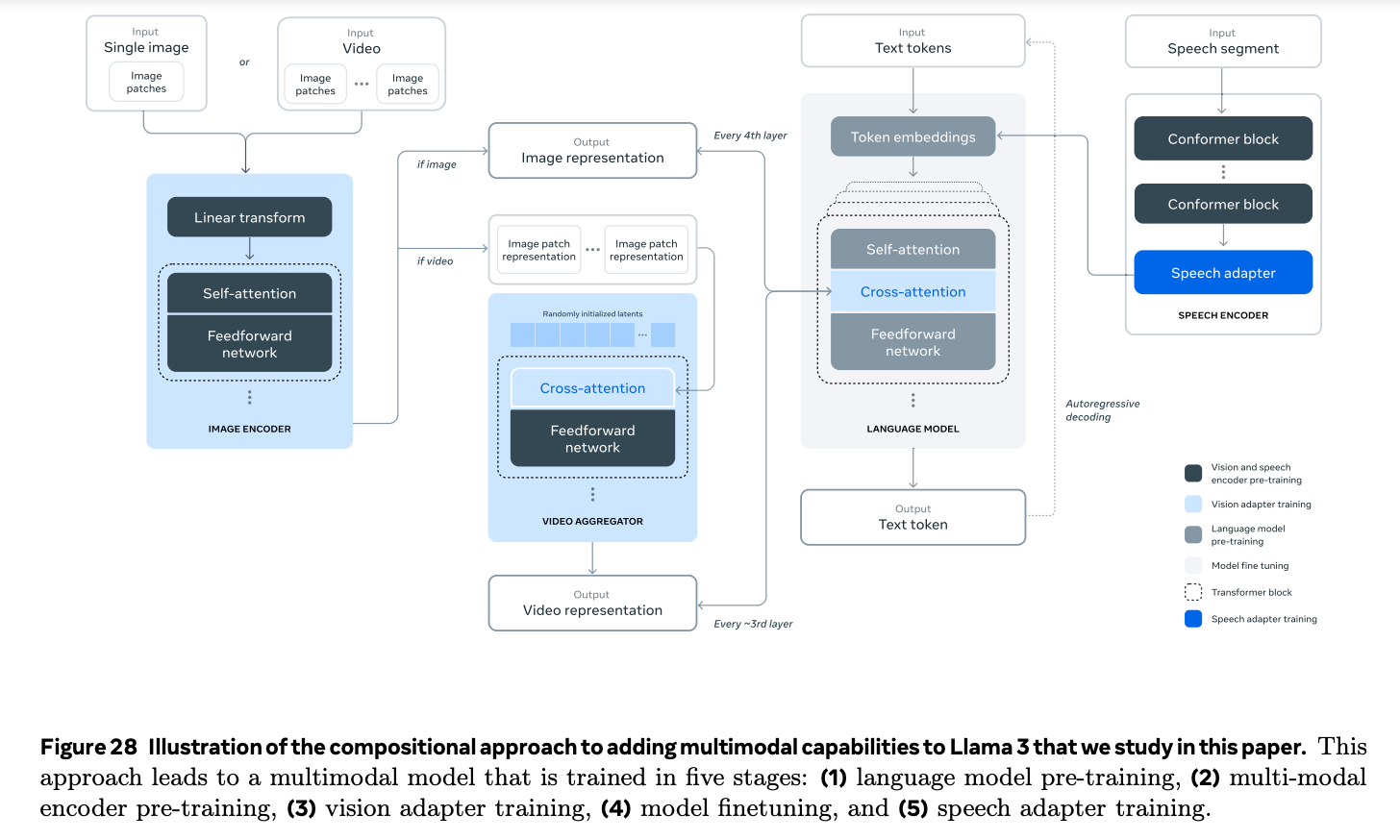
Meta’s developer-first play
It’s telling that Mark Zuckerberg published Open Source AI Is the Path Forward to underscore Llama 3’s release: “a key difference between Meta and closed model providers [e.g. OpenAI] is that selling access to AI models isn’t our business model”.
Llama 3’s focus on open-source multilingual, multimodal (with major advances in speech specifically), and AI safety and tooling centric foundation models are a step up (at least developer functionality coverage-wise) in the current landscape, but there’s no doubt that choosing to cater to developers right now is a critical choice that will make or break Meta AI. Llama is strongly poised to become Meta’s Android equivalent in the AI age — ubiquitous AI platform that can use developer-friendliness to take on wider markets (and collect more data!) — hugely contingent on outcomes in safety and scalability.