
Scaling laws for personalized recommendation models
Why we need to put the personal back into personalization

I recently joined a day-long birthday crawl for a friend that started at 11am with a favorite TV show and ended after 9pm with a saxophonist serenading our birthday girl at a well-known jazz lounge in San Francisco’s “Harlem of the West”. At “the western-most record shop on Planet Earth”, at a neighborhood coffee shop with a dedicated musubi fridge, at a bookstore and cafe that happened to stock 90% of my open Libby holds and pocket flower presses, in and around the hammocks at the Sunset Dunes, at two different movie theaters; at each stop we gathered to celebrate our friend, a generous connector of people and experiences, her kindness and community spirit, her impeccable taste and appreciation for quality art and film.
Friends like this remind me of the immeasurable impact of openly developing and sharing personal taste. In the past week alone, sparse peer-to-peer recommendations (read: friends that know my taste, and whose tastes I trust, telling me I’d really like something) have led me to a clothing purchase I’m happy with, an unexpectedly hilarious TV show that broke me out of a TV-watching slump, and a ticket counter purchase 15 minutes before showtime of a film that lived up to all the indie hype. However, and importantly, often a recommendation that by any other metric should hit just doesn’t do it for me; whether that’s a product of an expectations mismatch (don’t buy into the same hype), preferences mismatch (different personal weighting of dimensions), or inherent randomness (off day), these are the factors that are hard to model when we try to scale personal taste.
What large-scale recommendation systems get right
Using the Paine framework, I’ll begin with a starting thesis.
Thesis: More data feeds better recommendations.
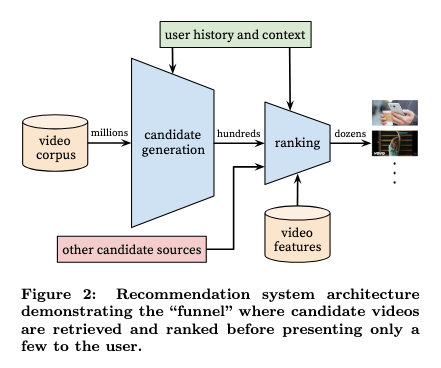
YouTube has consistently surfaced high-quality content made by lesser-known videographers to my home page of recommendations. YouTube’s sell to the user is that we’ll get increasingly personalized recommendations in exchange for allowing YouTube to collect our “user history and context” (watch history and interactions), which is fed into its recommendation system:
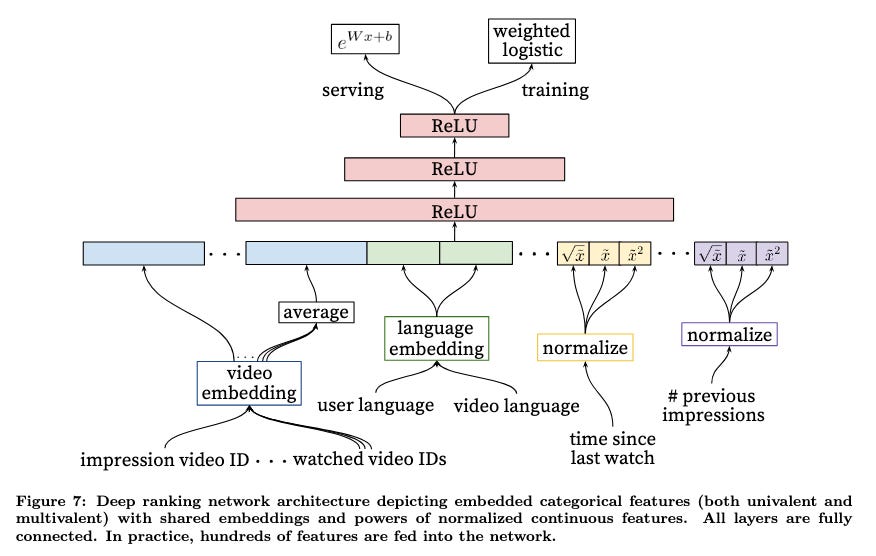
The model objective is to “predict expected watch time” using weighted logistic regression where clicked impressions (positive training examples) are weighted by video watch time and unclicked (negative) impressions are unit weighted:
Optimizing for video watch time across users understandably helps YouTube’s business goals as an entertainment and advertising platform incentivized to maintain a marketplace for users to watch videos and creators to create content.
However, a recommendation system trained on a population-scale dataset only works well if it knows enough about “user history and context” to draw meaningful preference connections between users. Extrapolating what one user might like to see next (or would watch the longest) from a set of inferred similar users and their watch behaviors yields to outcomes such as my YouTube homepage being filled with a hundred viral, sensationalist videos for each high-quality recommendation.
So while YouTube has the advantage of being the only platform where you can find a detailed, well-researched tutorial by anyone on anything, it lacks the inherent curation of platforms like Netflix and MUBI. For selective consumers, using YouTube to find quality content feels like a game of cornhole.
Less noise, more signal
“TV was in a language I didn’t understand, there was nothing to buy, no advertisements anywhere, so all I’d be doing was walk around, think and write. My brain felt like it was at rest, free from the consuming frenzy… Maybe it could have seemed like boredom at first, but it quickly became very soulful.” — Celine, Before Sunset (2004)
Counter-argument: Recommendations systems are the capitalistic product of social media. Eschew data in favor of specifically curated experiences.
In 2021, I spent at least half of my free time on TikTok and Twitter until I finally tired of my TikTok For You page and deleted my account. In parallel, I realized my Twitter feed was becoming an infinite scroll of distraction with decreasing reward.
I experience this pattern with most platforms I try. There’s an introductory period, assuming I get past the signup flow, where my delight factor is high enough to keep me using the platform. (The x-axis here is time elapsed since signing up, not the time / effort it literally takes to engage with the content per interaction, which is a long-form vs. short-form media conversation that requires a separate essay.) After some time, my delight factor starts to oscillate around a point where it’s increasingly unclear to me what value I’m deriving from the platform. Enough time spent under the quit threshold and I’ll stop coming back for more. This might be months or years. Regardless, without a periodic boost (new socials, new content, new interactions) the baseline delight of novelty generally bottoms out below the quit threshold.
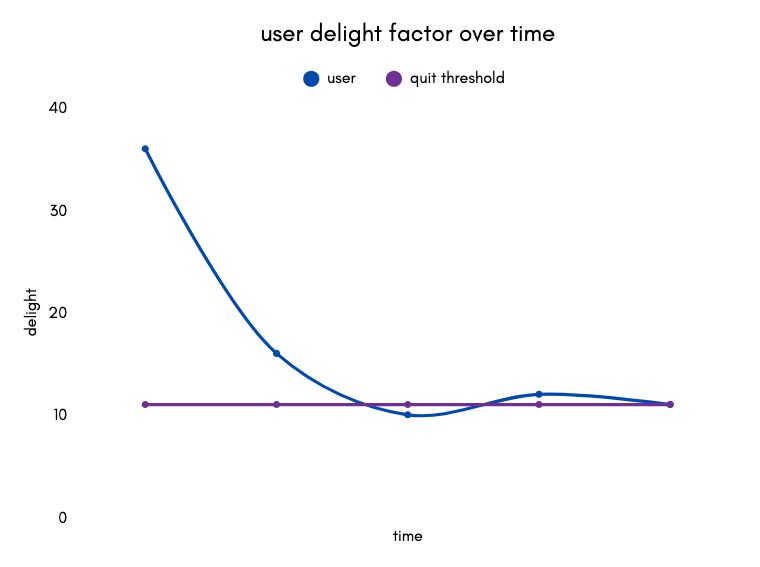
But my delight factor matrix across all my services is entirely personal and variable over time, a mixed product of confounding variables including my mood, what’s going on in my life when I’m consuming the content, who I’m sharing it with.
The dumbphone movement and the sheer fact that we as a population have established and documented social media detox methods show us that there is a strong and growing market here. Whereas traditional advertising may have prioritized capturing attention in a competitive entertainment landscape, now we’re seeing products that are explicitly vending distraction as a service. Scroll Instagram during your commute to make time go faster. Stare at Twitter to avoid making eye contact with anyone else when you’re waiting at the doctor’s office.
The problem with ignoring data when curating taste is that a certain degree of “online” is now a prerequisite to modern forms of discovery. Critically, media is now both fueled and judged by its online reception. Organic (word-of-mouth) and sponsored social media marketing drives box office outcomes, concert turnouts, and series renewals. You could see it as an internet-age tragedy of the commons where everyone is allowed to create, everyone is allowed to consume, and fringe content either develops enough of a cult following to become mainstream and economically sustainable or (so much more commonly) ends because the creator is not incentivized to continue developing content in a data-driven online economy.
Curation in the age of hypnotic media
“Good writers tend to be good and broad readers, and their sources tend to be a better curation tool than any other.” — Henrik Karlsson
Rebuttal: There’s a way to use social media platforms to inform ourselves and others, but effective and productive personalization requires effort and time to curate that may not be worth it for everyone.
My [fig 3] above is my own delight factor charted over time for an arbitrary service. This curve changes from individual to individual and that’s the retention curve no recommendation system is going to get precisely correct for anyone, because I can’t even properly quantify it for myself. My current formula is no TikTok, reduced Twitter consumption, and no saved YouTube watch history, just a collection of YouTube videos I know I like and following a limited path from YouTube’s recommendations formed from just a few data points. I use Netflix to watch specific peer-sourced recommendations and then personally find Netflix recommendations utterly useless. I’ve found a little more success with MUBI because it’s a highly curated collection of films, but enough flops to keep me wary of my subscription.
The social element of Spotify and Letterboxd encourage music and film discovery and are a way for friends to provide loose curation to each other. The problem of mapping peer-to-peer recommendations to individual preferences remains to be solved. Crucially, there’s no consistent way to collect quantifiable feedback on these recommendations. So much is kept in our brains but not communicated. So many things we may also not realize we would like, or need to be in a certain headspace or time of life to appreciate.
Even the acts of researching and writing this post have made me reflect on why I’m doing this:
“When your goal is not only to present ideas but to make them palatable and digestible for a distracted audience, the boundaries of intellectualism start to blur. Ideas are no longer for discussion, they’re for consumption.” — The death of the public intellectual
The main point I’m trying to get across is that it’s a constant but rewarding battle to go from passively consuming recommended content to proactively curating your methods of sourcing and discovering new media. Personally, it’s not even that my recommendation signal-to-noise ratio overall necessarily increases in doing so, but that the sparklier outcomes (unexpected, surprisingly good, random recommendations, often social) weight higher in my personal ranking.
Parting words. I’ll simply leave you with this:
“[Thank you] guys, AI could never” — friend asking a group chat for “recs for a dumb fun silly movie to stream tonight”