
Sunday papers; tech's bitter lesson
Read your heart out


“My perfect day? Sunday, my favorite day of the week. Raining, overcast. I go to my local coffee shop and order a black coffee and a pastry. I sit down with some research papers (at least one from Anthropic) and go to town.”
Paper review
I’m starting this post by reading and annotating publications by authors I respect as writers. If you’re looking for original writing, please skip ahead to Tech’s bitter lesson.
“The Bitter Lesson” (2019) by Rich Sutton (Rich Sutton & Andrew Barto received the 2024 Turing Award and wrote my favorite textbook):
Most AI research has been conducted as if the computation available to the agent were constant (in which case leveraging human knowledge would be one of the only ways to improve performance) but, over a slightly longer time than a typical research project, massively more computation inevitably becomes available. Seeking an improvement that makes a difference in the shorter term, researchers seek to leverage their human knowledge of the domain, but the only thing that matters in the long run is the leveraging of computation. These two need not run counter to each other, but in practice they tend to.
Computer v. Kasparov, 1997: When a simpler, search-based approach with special hardware and software proved vastly more effective, these human-knowledge-based chess researchers were not good losers. They said that “brute force” search may have won this time, but it was not a general strategy, and anyway it was not how people played chess. These researchers wanted methods based on human input to win and were disappointed when they did not.
AlphaGo, 2015: Search and learning are the two most important classes of techniques for utilizing massive amounts of computation in AI research. In computer Go, as in computer chess, researchers’ initial effort was directed towards utilizing human understanding (so that less search was needed) and only much later was much greater success had by embracing search and learning.
DARPA speech recognition competition, 1970s: the statistical methods won out over the human-knowledge-based methods. This led to a major change in all of natural language processing, gradually over decades, where statistics and computation came to dominate the field. The recent rise of deep learning in speech recognition is the most recent step in this consistent direction. Deep learning methods rely even less on human knowledge, and use even more computation, together with learning on huge training sets, to produce dramatically better speech recognition systems. As in the games, researchers always tried to make systems that worked the way the researchers thought their own minds worked---they tried to put that knowledge in their systems---but it proved ultimately counterproductive, and a colossal waste of researcher’s time
As a field, we still have not thoroughly learned it, as we are continuing to make the same kind of mistakes. To see this, and to effectively resist it, we have to understand the appeal of these mistakes. We have to learn the bitter lesson that building in how we think we think does not work in the long run… The eventual success is tinged with bitterness, and often incompletely digested, because it is success over a favored, human-centric approach.
One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great. The two methods that seem to scale arbitrarily in this way are search and learning.
The second general point to be learned from the bitter lesson is that the actual contents of minds are tremendously, irredeemably complex; we should stop trying to find simple ways to think about the contents of minds, such as simple ways to think about space, objects, multiple agents, or symmetries… We want AI agents that can discover like we can, not which contain what we have discovered. Building in our discoveries only makes it harder to see how the discovering process can be done.
“Burning out: An essay on overworking in AI” by Nathan Lambert, published yesterday:
Where OpenAI’s culture is often described as culty, there are often many signs that the core team members there absolutely love it, even if they’re working 996, 997, or 002. When you love it, it doesn’t feel like work. This is the same as why training 20 hours a week [as an athlete] while a full time student can feel easy.
Crafting the team culture in both of these environments is incredibly difficult. It’s the quality of the team culture that determines the outcome more than the individual components. Yes, with LLMs you can take brief shortcuts by hiring talent with years of experience from another frontier lab, but that doesn’t change the long-term dynamic. Yes, you obviously need as much compute as you can get. At the same time, culture is incredibly fickle. It’s easier to lose than it is to build.
I used to think that the AI bubble would pop financially, as seen through a series of economic mergers, acquisitions, and similar deals. I’m shifting to see more limitations on the human capital than the financial capital thrown at today’s AI companies.
Culture is a fine line between performance and toxicity, and it’s often hard to know which you are until you get to a major deliverable to check in versus competitors.
For me, the only reason to keep going is to try and make AI a wonderful technology for the world. Some feel the same. Others are going because they’re locked in on a path to generational wealth. Plenty don’t have either of these alignments, and the wall of effort comes sooner.
AWS postmortem on the outage that took down the Internet:
DynamoDB DNS automation miss: Automation is crucial to ensuring that these DNS records are updated frequently to add additional capacity as it becomes available, to correctly handle hardware failures, and to efficiently distribute traffic to optimize customers’ experience… In addition to providing a public regional endpoint, this automation maintains additional DNS endpoints for several dynamic DynamoDB variants including a FIPS compliant endpoint, an IPv6 endpoint, and account-specific endpoints. The root cause of this issue was a latent race condition in the DynamoDB DNS management system that resulted in an incorrect empty DNS record for the service’s regional endpoint (dynamodb.us-east-1.amazonaws.com) that the automation failed to repair.
EC2 delays post DynamoDB recovery: Customers experienced increased EC2 API error rates, latencies, and instance launch failures… After resolving the DynamoDB DNS issue at 2:25 AM PDT, customers continued to see increased errors for launches of new [EC2] instances. Recovery started at 12:01 PM PDT with full EC2 recovery occurring at 1:50 PM PDT.
NLB fallout from EC2: The delays in network state propagations for newly launched EC2 instances also caused impact to the Network Load Balancer (NLB) service and AWS services that use NLB. Between 5:30 AM and 2:09 PM PDT on October 20 some customers experienced increased connection errors on their NLBs in the N. Virginia (us-east-1) Region.
Other AWS services that rely on DynamoDB, new EC2 instance launches, Lambda invocations, and Fargate task launches such as Managed Workflows for Apache Airflow, Outposts lifecycle operations, and AWS Support Center were also impacted in the N. Virginia (us-east-1) Region.
“How Complex Systems Fail” by the late physician and software engineer Dr. Richard Cook, published 1998-2000:
All of the interesting systems (e.g. transportation, healthcare, power generation) are inherently and unavoidably hazardous… The frequency of hazard exposure can sometimes be changed but the processes involved in the system are themselves intrinsically and irreducibly hazardous.
Post-accident attribution to a ‘root cause’ is fundamentally wrong: There are multiple contributors to accidents. Each of these is necessarily insufficient in itself to create an accident. Only jointly are these causes sufficient to create an accident.
Hindsight bias remains the primary obstacle to accident investigation, especially when expert human performance is involved: The outcome knowledge poisons the ability of after-accident observers to recreate the view of practitioners before the accident of those same factors. It seems that practitioners “should have known” that the factors would “inevitably” lead to an accident.
In fact that likelihood of an identical accident is already extraordinarily low because the pattern of latent failures changes constantly. Instead of increasing safety, post-accident remedies usually increase the coupling and complexity of the system. This increases the potential number of latent failures and also makes the detection and blocking of accident trajectories more difficult.
Failure free operations require experience with failure: More robust system performance is likely to arise in systems where operators can discern the “edge of the envelope”. This is where system performance begins to deteriorate, becomes difficult to predict, or cannot be readily recovered. In intrinsically hazardous systems, operators are expected to encounter and appreciate hazards in ways that lead to overall performance that is desirable. Improved safety depends on providing operators with calibrated views of the hazards.
“Preparing for AI’s economic impact: exploring policy responses”, Anthropic’s follow up to their September Economic Index report I covered in a previous post:
Policies for nearly all scenarios:
1) Invest in upskilling through workforce training grants (e.g. subsidies to employers to create formal trainee positions with structured training programs; redirect higher ed subsidies to fund this; tax AI consumption)
2) Reform tax incentives for worker retention and retraining
3) Close corporate tax loopholes
4) Accelerate permits and approvals for AI infrastructure.
The suggestion to redirect higher education subsidies to fund workforce training programs is questionable given the current state of higher education funding. AI consumption tax is tractable, but face heavy opposition by certain states buoyed by AI investment. 2) and 3) don’t necessarily benefit Anthropic, its investors or corporate partners, giving these proposals some credibility, but also equally hits wider corporate AI competition (Google, Meta, X). 4) is clearly in Anthropic’s favor and would bolster AI development and funding generally.
Policy ideas for moderate scenarios:
5) Establish trade adjustment assistance for AI displacement: how the Trade Adjustment Assistance (TAA) model – in which affected workers are given opportunities to obtain new skills, or receive other support – might be adapted for labor market disruptions in an era of powerful AI. (“AI insurance” as a mechanism “to support those who lose jobs due to AI.”)
6) Implement taxes on compute or token generation… We believe taxes in this broader category deserve serious study, even though they would directly impact Anthropic’s revenue and profitability.
Policy ideas for fast-moving scenarios:
7) Create national sovereign wealth funds with stakes in AI… [for the UK] The AI Bond would aim to ensure adequate investment in “the AI stack” to capture AI’s benefits and then distribute its returns more evenly across Britain—even as AI research roles concentrate in a few cities, like London.
8) Adopt or modernize value-added taxes (VAT)… US is [currently] the exception… As AI transforms the economy, labor’s share of the production of value might decline significantly. A shift toward taxing consumption (as through a VAT) could become necessary to fund core government activities.
Briefly, sales tax in the US is collected by the retailer at final point of sale vs. VAT tax which is collected at each stage of supply chain.
9) Implement new revenue structures to account for AI’s growing share of the economy… [if labor’s share of economic output declines significantly] governments might require new revenue streams to complement income tax… [could explore] a “low-rate business wealth tax” as a complement to income taxes.
Many of these policy ideas are around government regulation, taxation, and wealth distribution methods (e.g. via subsidies and public investment instruments - the “AI bond”) which Anthropic explicitly recognizes would be downward pressure on its profits. Anthropic’s “$10 million commitment to scale up the Economic Futures Program” seems low compared to Google’s $75M AI Opportunity Fund and OpenAI’s $50M nonprofit fund, although Anthropic’s commitment is specific to funding economics research and symposia.
Tech’s bitter lesson
Recall Rich Sutton’s bitter lesson pulled from 70 years of AI research: in the strategy games of chess and Go, in complex modeling tasks such as speech recognition, method advancements made by human researchers were not as effective as scaling up compute power. He proposed a goal of building machines that learn and explore like us, not from us, that could be organized and leveraged to make greater breakthroughs, instead of being limited to the collective capacity of our own minds.
Abhishaike Mahajan came to a form of bitter lesson conclusion on developing cancer treatments, in “Cancer has a surprising amount of detail”:
In most areas of medicine, a diagnosis tends to unify patients under a single therapeutic approach: antibiotics for bacterial pneumonia, insulin for type 1 diabetes, thyroid hormone for hypothyroidism. The drug may differ in dose or formulation, but not in principle.
This is not the case for cancer.
I’d like to focus on one fault that all the papers mention: the inability for many novel biomarkers to improve on the current clinical standard.
In other words, the obvious next step is to stop asking for singular biomarkers to bear the entire burden of explanation, and instead ask how many small signals can be woven into a coherent, usable picture. But this creates a combinatorial explosion! If you have 20 binary biomarkers, that’s over a million possible patient subgroups. No trial, no matter how well-funded, can enumerate that space.
How can we escape this problem? It is increasingly my opinion that the only reasonable path forward is to delegate the problem of cancer biomarkers to machine intelligence.
Dwarkesh Patel interviewed Rich Sutton last month:
Sutton: I don’t think learning is really about training. I think learning is about learning, it’s about an active process. The child tries things and sees what happens.
Patel: Once we have AGI, we’ll have researchers which scale linearly with compute. We’ll have this avalanche of millions of AI researchers. Their stock will be growing as fast as compute… As a vision of what happens after AGI in terms of how AI research will evolve, I wonder if that’s still compatible with a bitter lesson.
Sutton: How did we get to this AGI? You want to presume that it’s been done… The bitter lesson, who cares about that? That’s an empirical observation about a particular period in history. 70 years in history, it doesn’t necessarily have to apply to the next 70 years… I do think succession to digital intelligence or augmented humans is inevitable… We should be concerned about our future, the future. We should try to make it good. We should also though recognize the limit, our limits.
Meta’s AI layoffs this week were the latest development in years of restructuring in the post-COVID, post-agentic tech industry. Most tech layoffs in 2025 cite flattening management (Google eliminated 35% of its managers leading small teams) and roles eliminated with increased AI adoption (Salesforce laid off 4,000 in customer support this year). It’s true that AI can do many things humans can do. It’s true that AI assistants, coders, and writers are more accurate and efficient than humans in many cases. It’s true that many managers are a net drag on their teams, introducing overhead via process, bureaucracy, morale.
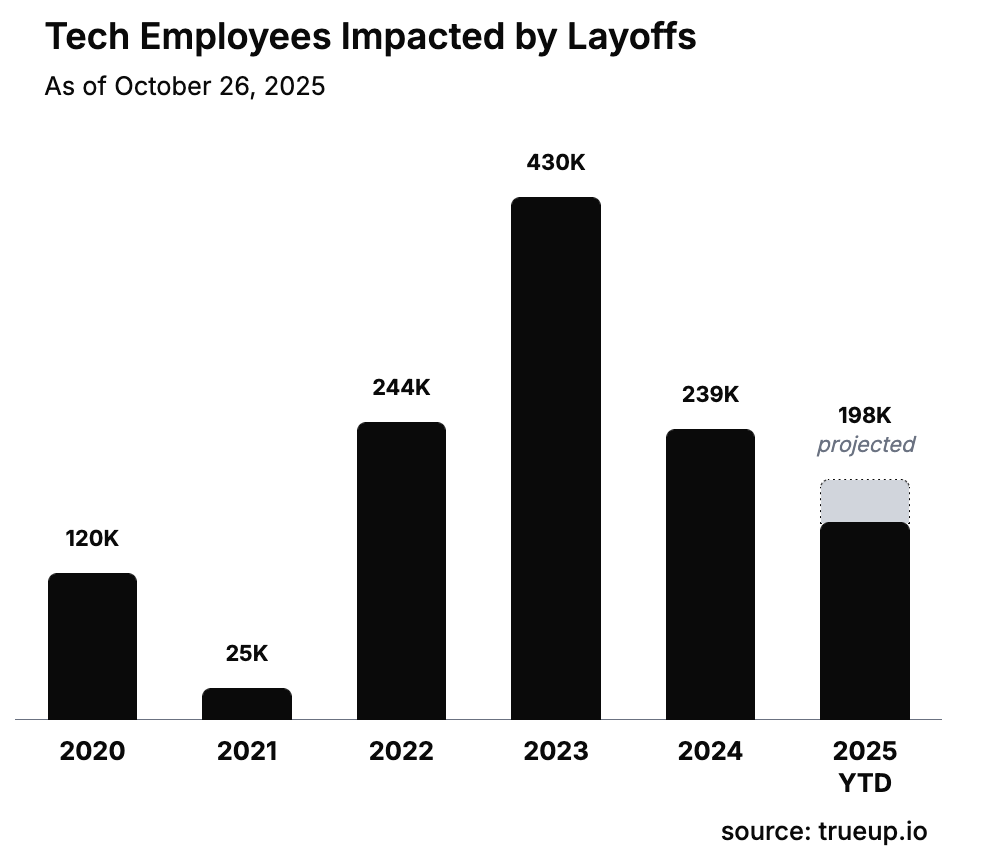
But these are not new developments in the industry. Ineffective and inefficient management is a tale as old as commerce. Automation is definitely not new in customer support. The earliest “agentic AI” sales solutions were rule-based call routing, and honestly they were better than a lot of the solutions today.
Companies are incentivized to hire when business is good and talent is cheap. Often they are pressured by stock price and stakeholder commitment to prioritize short-term gains over proper long-term management. Big tech hired aggressively in the years following the 2020 COVID-19 pandemic, benefiting from temporary pandemic-era customer behavior shifts:
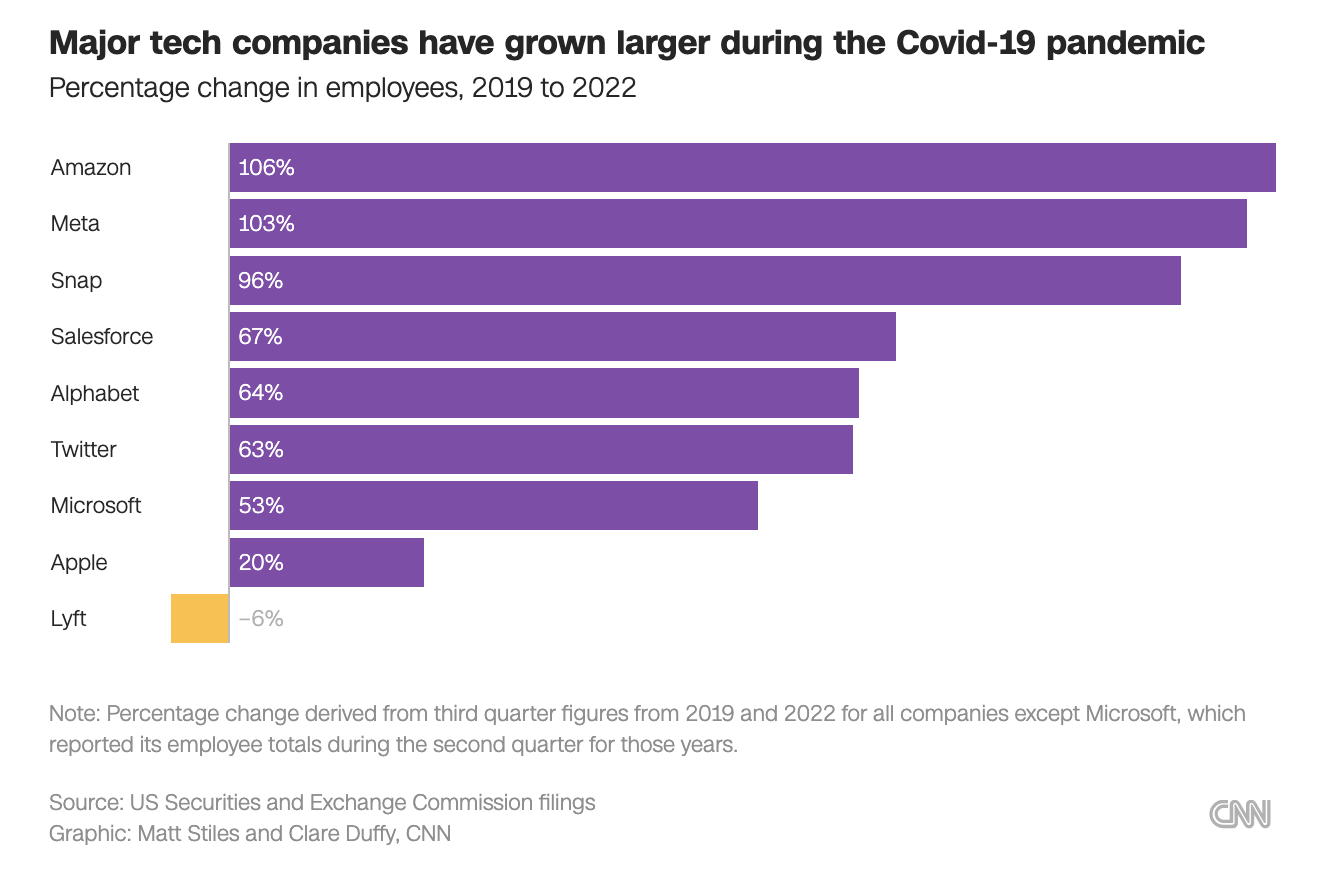
In 2023 many companies announced major layoffs, although CNN called out at time of publication that Apple grew its staff by only 20% from 2019 to 2022 and had not announced layoffs:
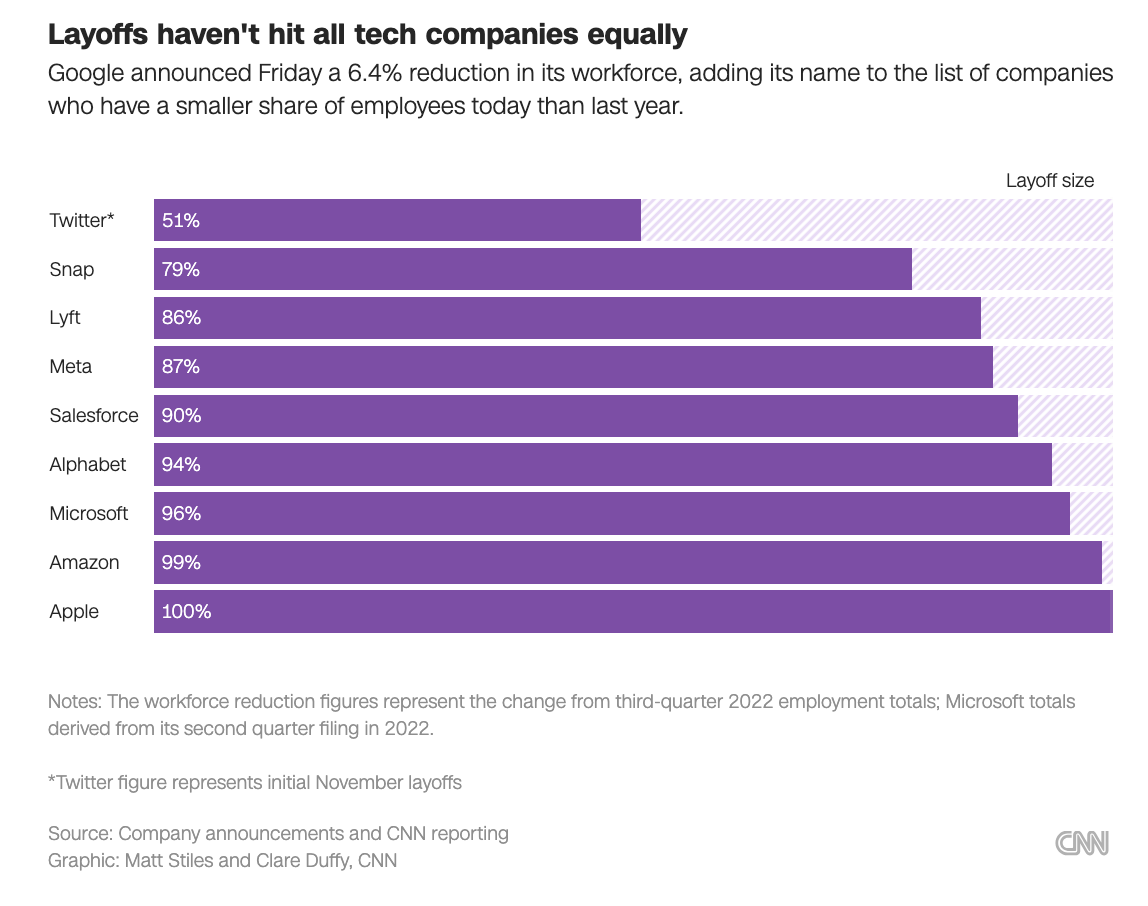
It’s tempting to conceptualize a “bitter lesson” for tech. Promo-driven development rewards engineers and managers hungry for greater responsibility, resulting in frivolous, buggy products and headaches and messes for others to weather. We’re seeing the risk of a messy software network start to become more publicly obvious in cases like AWS’s wide network of customers taking days to recover from a point of failure outage. Tying development outcomes to market behavior (and executive paychecks, funding and partnerships) encourages decision-making that ranks corporations above their constituents.
We have seen cases where widespread, normalized and instrumented financial and corporate risk capitalizing on short-term market-behavior led to societal financial collapse: in 2008, it was driven by inflated subprime loans that lost their value too quickly to recover from. We have been in a convoluted economic state for the last few years as sectors responded differently to the pandemic, recovery, and international trade developments.
The difference between the tech industry and the research picture that Rich Sutton drew his bitter lesson from is that the tech problem doesn’t have an objective function. We are not uniformly trying to build a chessmaster or the most accurate speech recognition system. If anything, corporate tech’s reward function is, like that of any corporate sector, profit — which is not actually quantifiable, when you consider things like optimizing for long-term profit being a valid corporate strategy that relies on trust and human capital to implement successfully while avoiding the trap of short-term capital needs. Tech’s bitter lesson is actually that, empirically in our 30 years of widespread Internet-based technology since dotcom, good social and research outcomes are byproducts of corporate development and an international markets game. And what of players like Anthropic, now actively proposing regulation and tax overhauls that may or may not benefit them? No different than oil and finance’s long-term lobby, just much more public. We may appreciate Anthropic’s human-first, socially-conscious marketing, but we don’t need to see it as anything more than a creatively-marketed software company.
So if the global economy and technological development is controlled by players and incentives we don’t understand, do we have any clear path to building a technological future we are empowered to influence to align to our values? Absolutely. While tech companies have capitalized on human attention and unsustainable workforce management to drive profit, great research advances and applications are enabled by competition in developing faster, cheaper, better versions of the underlying technologies. As Dr. Sutton highlighted to Dwarkesh, what defined the bitter lesson of the last 70 years in research need not continue into the next 70. The corporate tech patterns of the last 30 years need not define our next 30; in our current economic and resource systems, we can’t sidestep certain capital requirements to run successful organizations, but we can reward, both as consumers and producers, players with the power and potential to build a balanced world of humans and machines in harmonious symbiosis. We can shift tech’s bitter lesson by shifting its overall reward function.
This reflection ties many threads together: Research culture, corporate incentives, and the moral architecture of innovation, and still feels human. The contrast between Sutton’s empirical bitter lesson and tech’s profit-driven one lands especially well. You manage to hold both cynicism and optimism at once, with the realism that systems chase reward functions, and the belief that those functions can evolve.