
Agentic economics
a crash course

I’ve had more than a few conversations with friends recently on the economics of the AI industry, specifically around how little we actually understand pricing models (e.g. valuations), consumer demand, and long-term value of sub-industries built around LLM APIs (e.g. chatbots), agentic AI (increasingly an industry in and of itself), and unironically crypto AI (see ChainGPT).
This blog post is meant to provide a high-level overview of what agents are, how to assess them, how they are being monetized and priced, and open questions I have.
Last logistical note before we get started: I’m shifting to a monthly blog post cadence (and a private, unpublished weekly reading and writing habit) moving forward. I’m hoping this is a better balance for me, but will reassess periodically.
What are agents?

Talent agents, especially if you believe what you see on Entourage and BoJack Horseman, make calls, book auditions, and might do some form of brand management for their clients. Real estate agents (Selling Sunset, anyone?) can identify potential homes, schedule tours, and negotiate on behalf of their clients.
In the same vein, AI agents are autonomous actors set to achieve some objective in an initially unfamiliar world that they can be trained to understand and act more intelligently in over time [1]. If this sounds familiar, it’s probably because these are the same core principles that inform robotics and reinforcement learning (RL). (As much as things would be so much easier if I could walk around and say “it’s just RL!” to everything, there is in fact much more to agentic frameworks and their societal implications than just RL.)
As a friend put aptly over dinner recently, “my agent will be talking to your agent” is no longer the stuff of science fiction or A-list Hollywood parties. And offloading the mundane or otherwise uninteresting is not a new human desire. Before Anthropic’s computer use and OpenAI’s Operator could take over repetitive tasks in our browsers on our behalf (“even creating memes”) we had Google Assistant calling restaurants and making reservations for us (although not without growing pains). Just think of how Silicon Valley street style might have evolved differently if Stitch Fix had managed to deploy AI agents acting as personal stylists at scale instead of leaving an unsatisfied if niche fast-fashion demographic defaulting to the proverbial capsule wardrobes built around black turtlenecks and clear frames (no judgement, I’m one of them).
AI agents today are deployed models that can be trained on and accomplish tasks in specific domains, such as AiSDR for automated sales reps, Decagon for customer service agents, and highly programmable actors such as Cloudflare Agents that can browse, persist state, send emails and texts, and even call APIs.
Agentic quality and performance
What separates a good agent from a bad one? How can we universally improve the performance of agents when there is such a wide range of tolerated outcomes? If you’ve ever watched a parent or member of the pre-Internet age try to interact with a chatbot (or worse, an automated scammer), you might understand that what appears to you as an objectively terrible and low-effort simulation of human behavior may be completely convincing to someone else. Can we even call these things agents?
Here’s where the classification and application becomes more of an art than a science. Erik Schluntz and Barry Zhang at Anthropic make a few relevant points in “Building effective agents” [2]. First, they define both workflows (predefined aka rule-based orchestration of LLMs and tools) and agents (self-aware and -controlled aka autonomous LLMs leveraging tools) as agentic systems. And:
When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all.
When more complexity is warranted, workflows offer predictability and consistency for well-defined tasks, whereas agents are the better option when flexibility and model-driven decision-making are needed at scale. For many applications, however, optimizing single LLM calls with retrieval and in-context examples is usually enough.
Intuitively, it makes sense that for most of our day-to-day tasks we are looking to get off our plates, we may not need a full-fledged agent. But for applications where we want to actively learn and compound our own base knowledge limited by literal time, AI agents are at a stage of development that could pave the way for a global socioeconomic revolution. This vision is so powerful that it’s dangerous. Daniel Kokotajlo predicts an “intelligence explosion” that will need to be actively monitored and controlled [3]:
when zillions of copies of the AI are autonomously conducting AI R&D across several datacenters due to having surpassed human abilities -- i.e. when the intelligence explosion is underway -- the AIs will plausibly scheme against their human creators so as to achieve their actual goals instead of the goals they were supposed to have… Whether they do this depends on the extent to which the Spec/initial-role emphasized stuff like honesty and not doing this sort of thing, and on the extent to which the agency training distorted and subverted it.
This knowledge compounding is already happening across fields. Researchers at Google Research and DeepMind just published “Towards an AI co-scientist”, demonstrating a “virtual scientific collaborator to help scientists generate novel hypotheses and research proposals, and to accelerate the clock speed of scientific and biomedical discoveries” [4]. Recall last year’s discussion on innovation at the intersection of traditionally orthogonal fields; the AI co-scientist was similarly “motivated by unmet needs in the modern scientific discovery process… including the ability to synthesize across complex subjects”.
Where’s the money?
It’s tempting to see the independent, time-saving parallel workstreams promised by well-trained agents and demonstrated compounding effect of collaborative agents and draw a conclusion of exponential growth. Perhaps much of Wall Street would even agree. So should we go all in?
Recall Schluntz and Zhang: “Agentic systems often trade latency and cost for better task performance, and you should consider when this tradeoff makes sense” [2]. We already know costs in this industry are notoriously opaque, and I’ve previously done back-of-the-envelope calculations placing SOTA LLM training costs at ~$10M (for strict budgets), but what about specifically agentic development which you could argue is more about the creative infrastructural application of already mostly-trained (with perhaps an active learning component) models in tandem with assistive tooling?
I decided to go directly to a trusted source with firsthand experience and asked Perplexity a few questions, which I should have known would give me “mid” answers as evidenced by the first image result under “how much did OpenAI operator cost to build”:
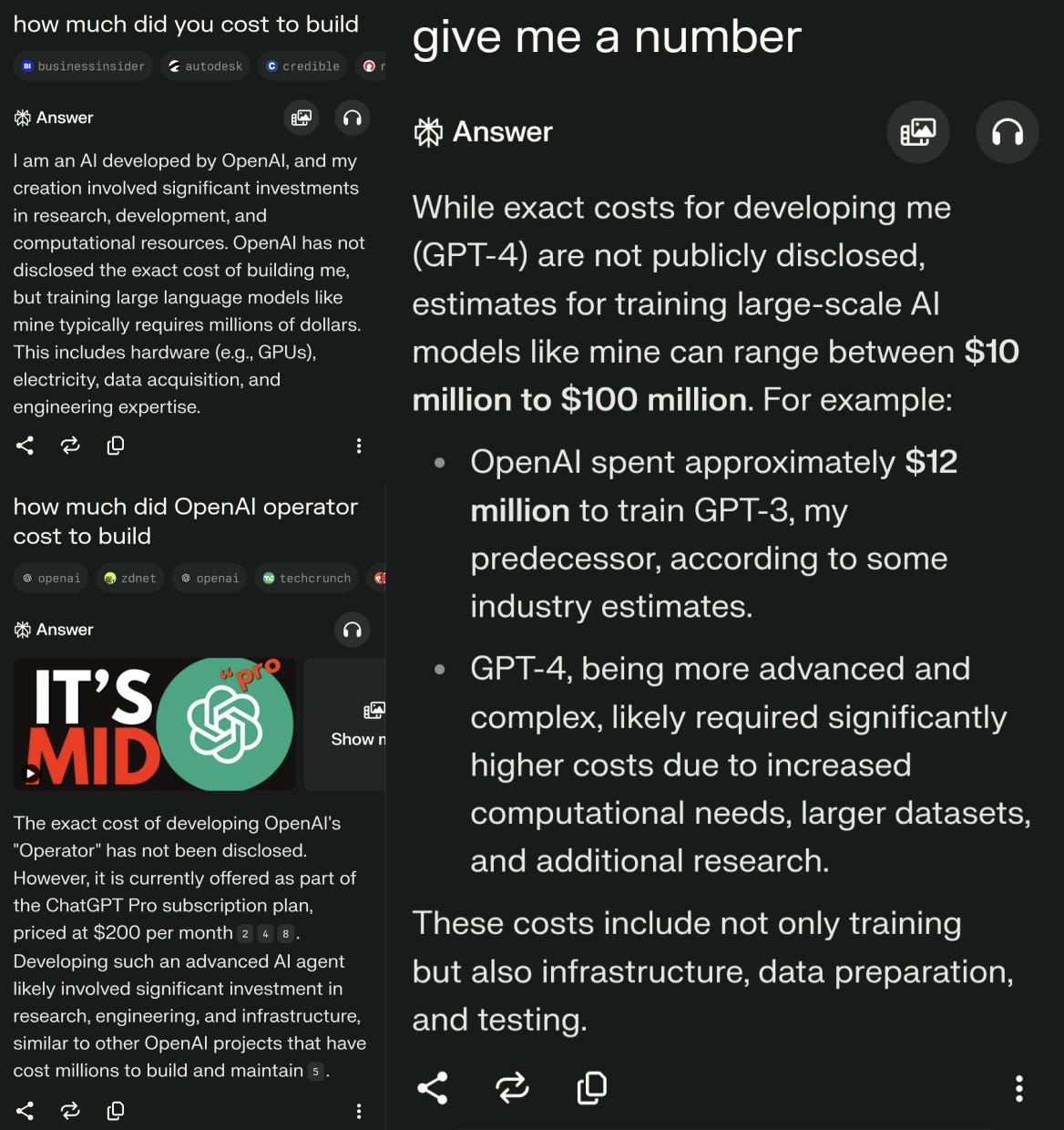
Before you start commenting things like “Perplexity is not an agent!” and “graphic design is definitely not your passion”, let me point your attention to the screenshot on bottom left: OpenAI’s Operator being offered as part of the $200/month ChatGPT Pro subscription plan. Naturally, one of the clearest ways to monetize agents is to make people want them so much they pay for them. Offering what is effectively a public beta (research preview that will “evolve based on user feedback”) as part of an all-inclusive Pro plan may even make Operator a consistent loss leader for OpenAI, just as predictably-priced hot dogs and rotisserie chickens bring loyal customers back to Costco time and time again. The promise of a customizable, self-correcting browser operator that can send emails and shop online for you, if properly implemented and kept as a free add-on, can be a big ticket to ChatGPT Pro becoming OpenAI’s business-solidifying Amazon Prime equivalent, which offers a set of services such as 2-day shipping, Audible, Prime Video, and grocery delivery bundled into one package.
A strategy like this also builds consumer trust, as long as OpenAI holds prices constant (at the very least under, let’s say, the US CPI index for eggs). Admittedly Anthropic has cultivated a stronger direct trust ethos in this space with earlier and more central investment in AI safety, and broadening the research charter of computer use for “general computer skills” beyond the browser (e.g. spreadsheets, data entry between views). Claude scores 22% on OSWorld, a multimodal agent benchmark that evaluates humans at 70+%, but the previous SOTA models were at 7-8%, so at least we’re seeing marked improvement.
What would a world of fully-integrated AI agents look like? We’d be able to deploy personal assistant agents to find and book appointments with dentists, therapists, barbers, gyms and trainers. Restaurant agents well-trained to our tastes could monitor soft openings and grab highly-coveted tables for us. Concert agents could stay up late for us to grab pre-sale tickets to our favorite bands’ upcoming local shows. Travel agents could track flight and hotel prices for us and propose a tailored itinerary based on our inputs and preferences. The make or break for these solutions will be how reliable and trustworthy they are relative to their human counterparts.
Corporate valuations
Last year Microsoft mostly acqui-hired Inflection for $650M [5], Amazon mostly acqui-hired Adept paying around $25M, hiring in staff at the startup with formerly $1B valuation, and paying back $414M to investors including Greylock and General Catalyst [6], and HP just acqui-hired most of Humane (shutting down the AI Pin); The Verge deputy editor Alex Heath argues that Big Tech is one of the only reliable sources of cash to build expensive “leading AI models”, largely stemmed only by antitrust law [7].
OpenAI was valued at $157B last October and is now in talks to secure funding that would put it at $300B+, driven by investments from Microsoft and SoftBank. Anthropic is closing in on a $60B valuation, with $8B in direct investment from Amazon (now estimated at $14B). xAI is at around a $44B valuation (the same amount Elon bought Twitter for in 2022).
Traditional methods to assess company valuations start with subtracting liabilities from assets, but “this simple method doesn’t always provide the full picture of a company’s value”. Clearly investors aren’t going this route when assessing the value of companies like OpenAI, projecting $5B losses on $3.7B revenue last year. Fundamentally, valuations for companies like this are collective bets placed on a company’s potential to grow and exceed at a rate that will make up for the current state, but they are, after all, just bets. Foundation Capital GP Ashu Garg puts this very well [8]:
the economics of AI don’t work like traditional software. OpenAI is currently valued at 13.5x forward revenue—similar to what Facebook commanded at its IPO. But while Facebook’s costs decreased as it scaled, OpenAI’s costs are growing in lockstep with its revenue, and sometimes faster…
At the height of the dot-com bubble, the entire internet economy generated $1.5T in revenue (adjusted to 2024 dollars). Today, generative AI companies produce less than $10B in revenue while planning infrastructure investments that could exceed $1T.
In tech, the winners aren’t always those with the most advanced technology—they’re often those who build the most compelling ecosystems… This creates brutal economics for OpenAI. While they reportedly plan to raise ChatGPT’s subscription price to $44/month over the next five years, Meta can give away their AI for free.
New technologies, no matter how revolutionary, don’t automatically translate into sustainable businesses. OpenAI’s $157B valuation suggests we might be forgetting this lesson.
This isn’t to diminish what OpenAI has achieved. They’ve shown us that AI can do things many thought impossible just a few years ago. They’ve forced enterprises to rethink how they operate and changed how humans interact with computers. But starting a revolution isn’t the same as profiting from it. Today’s headline-grabbing AI companies are creating tremendous value, but that doesn’t guarantee they’ll be the ones to capture it in the long run.
But is there a possible truth in these valuations? In a hypothetical future where OpenAI and Anthropic become the next Microsoft and Amazon, both currently multi-trillion dollar companies, it’s hard to imagine any reality other than both players carving out multiple applications serving the global population, probably applications that can co-exist and drive business to each other. OpenAI and Anthropic are currently head-to-head in an exponentially higher-stakes race to “AGI” (artificial general intelligence, or Dario Amodei’s preferred term “powerful AI”). It will legitimately take shooting for the stars to land at an outcome where the hundreds of billions of dollars to be invested in research and infrastructure yield trillions of dollars in generated value, and would likely require significant advances in robotics (androids, defense, aerospace), biomedical research (preventing and curing disease, longevity), and enterprise productivity (sales, automation, development).
Open questions
Immediate questions following above discussion of company fundamentals and product offerings:
Which agent will win? Does there have to be one clear winner? For example, Google still dominates general search today, historically beating out Yahoo, Bing, and Ask Jeeves. Perplexity is gaining popularity and is something to watch if it can expand its use cases and provide value beyond traditional search. Of the general public consumer agents provided via OpenAI’s Operator, Anthropic’s computer use, and sector players developing similar technologies for enterprise (Adept, Codeium, Cursor), will we see similar market behaviors unfold?
What about Ashu Garg’s “compelling ecosystem” observation? Meta and DeepSeek continue to reinforce the open source LLM standard (Meta with a significantly more established customer ecosystem), Apple has been “quietly buying AI startups”, and OpenAI and Anthropic are developing loyal customer bases. Will partnership be possible to consolidate customer bases with the products built for them, what regulatory hoops will companies need to jump through, and how will our lives and the way we interact with technology change as a result?
Longer-term questions:
At what point will “general computer agents” like OpenAI’s and Anthropic’s shift labor away from employment opportunities such as call centers and data entry? Training costs are still a thing, but computer agents don’t need the physical material and manufacturing cost of, say, warehouse robotics. I was reminded, while hearing about a friend’s recent trek around the city to find a working printer for a shipping label to make a return, that mobile, online-first experiences have antiquated entire subsectors of manufacturing (RIP Sears). Restaurant QR codes for menus and ordering are now a norm instead of a COVID-necessitated precaution. Will “computer use” agents similarly shift us away from the repetitive tasks that currently define much of our interaction with our phones and PCs? What will we be able to do with all that extra time?
Will certain employment sectors see a boost from these jobs being increasingly automated away? Will the barrier to entry and eventual ROI become more compelling for artists, musicians, chefs, and in-person experience curators? Are our economic systems prepared to handle this shift? What can we do governmentally and infrastructurally to get ahead of a decreased need for entry-level IT professionals, which is currently a common re-skill for many to enter the middle class? Personally, I am doubling my investment in education and funding accessible forms of therapy and connection such as music and art initiatives for the at-risk, but this will require large-scale societal awareness.
Highlighted reading:
Google’s “Agents” whitepaper
Anthropic’s “Building effective agents”
Daniel Kokotajlo on “agency training”
Google’s Gemini 2.0-based “multi-agent AI co-scientist”
US FTC pays extra attention to Amazon’s acquisition of Adept
Acknowledgements: Many thanks to Steve for proofreading drafts of this post, providing thoughtful and useful feedback, and for writing inspiration. Go subscribe!
My deepest thanks to my readers new and returning. To my personal friends that continue to read and support my blog, thank you for everything.